
Selecting Subsets of Data in Pandas: Part 4
This is the fourth and final part of the series “Selecting Subsets of Data in Pandas”. Pandas offers a wide variety of options for subset selection, which necessitates multiple articles. This series is broken down into the following topics.
- Selection with
[],.locand.iloc - Boolean indexing
- Assigning subsets of data
- How NOT to select subsets of data
Become an Expert
If you want to be trusted to make decisions using pandas and scikit-learn, you must become an expert. I have completely mastered both libraries and have developed special techniques that will massively improve your ability and efficiency to do data analysis and machine learning.
- Master Data Analysis with Python — A comprehensive course with 600+ pages, 300+ exercises, multiple projects, and detailed solutions that will help you become a pandas expert.
- Master Machine Learning with Python — My comprehensive guide to become an expert at both the concepts and tools of building a machine learning workflow using Python with scikit-learn.
- Get a sample of the material by enrolling in the FREE Intro to Pandas course.
- Learn directly with me by taking an interactive and fun in-person bootcamp.
Social Media
I frequently post my python data science thoughts on social media. Follow me!
Corporate Training
If you have a group at your company looking to learn directly from an expert who understands how to teach and motivate students, let me know by filling out the form on this page.
Learning what not to do
In all programming languages, and especially pandas, the number of incorrect or inefficient ways to complete a task heavily outnumbers the efficient or idiomatic ones.
The term idiomatic refers to code that is efficient, easy to understand, and a common way (among experts) to accomplish a task in a particular library/language.
The first three parts of this series showed the idiomatic way of making selections. In this section, we will cover the most common ways users incorrectly make subset selections. Some of these bad habits might be perfectly acceptable in other Python libraries but will be unacceptable with pandas.
Getting the right answer with the wrong code
One of the issues that prevent users from learning idiomatic pandas, is that it is still possible to get the correct final result while using highly inefficient and non-idiomatic code. Completing a task isn’t necessarily indicative that your code is correct.
Here are a few reasons why a solution that gives the correct result might not be good:
- A slow solution might not scale to larger data
- A solution might work in this particular instance but fail with slightly different data
- A solution might be very fast, but hard to interpret by others
Chained indexing with lists
Chained indexing is the first and most important subset selection problem we will discuss. Chained indexing occurs whenever two subset selections immediately following each other.
To help simplify the idea, we will look at chained indexing with Python lists. Let’s first create a list of integers:
>>> a = [1, 5, 10, 3, 99, 5, 8, 20, 40]
>>> a
[1, 5, 10, 3, 99, 5, 8, 20, 40]
Let’s make a normal subset selection by slicing from integer location 2 to 6.
>>> a[2:6]
[10, 3, 99, 5]
Chained indexing occurs whenever we make another subset selection immediately following this one. Let’s select the first element from this new list in a single line of code:
>>> a[2:6][0]
10
This is an example of chained indexing.
Assigning a new value to a list with chained indexing
Let’s say, we wanted to change this value that was selected from above from 10 to 50. Let’s attempt to do this assignment with chained indexing:
>>> a[2:6][0] = 50
>>> a
[1, 5, 10, 3, 99, 5, 8, 20, 40]
Nothing happened???
As you can see, the list a was not modified at all. The reason for this, is that Python created a temporary intermediate list directly after the first subset selection. It might be easier to write out the execution of the above into two separate steps:
>>> a_temp = a[2:6]
>>> a_temp[0] = 50
>>> a_temp
[50, 3, 99, 5]>>> a
[1, 5, 10, 3, 99, 5, 8, 20, 40]
The temporary object was the only one modified
As you can see, the intermediate object, a_temp, was the only object modified. The original was left untouched.
But doesn’t Python modify objects that are the ‘same’?
Let’s take a look at a closely related example where Python will modify two variables at the ‘same’ time. Let’s create a new list, a1 and set it equal to b1 and then modify the first element of it:
>>> a1 = [0, 1, 2, 3]
>>> b1 = a1
>>> b1[0] = 99
>>> b1
[99, 1, 2, 3]>>> a1
[99, 1, 2, 3]
Both have changed!?!
In the above example, we made a single call to change the first element of b1. This modified both b1 and a1. This happened because a1 and b1 are referring to the exact same object in memory. a1 and b1 are simply names that are used to refer to the underlying objects, which in this case, are the same.
Proof they are the same with the id function
We can prove that a1 and b1 are referring to the same object with the built-in id function, which returns the memory address of the object.
>>> id(a1)
4501625608>>> id(b1)
4501625608>>> a1 is b1
True
So, why did our assignment with chained indexing fail?
Whenever you take a slice of a list, Python creates a brand new copy (a shallow-copy to be exact) of the data. A copy of an object is completely unrelated to the original and has it’s own place in memory.
Whenever we write a[2:6], the result of this is a brand new list object in memory unrelated to the list a. The statement a[2:6][0] = 50 does actually make an assignment to that temporary list copy, but it is not saved to a variable, so there is no way to track it.
To properly assign the 2nd position in the list a to 50, you would simply do a[2] = 50 instead of chained indexing.
Shallow vs Deep Copy (Advanced)
You can safely skip this section as it won’t be relevant to our subset selection. Python creates a shallow copy when performing a slice on a list. If you have mutable objects within your list, then these inner list objects won’t be copied and will still be referring to the same object.
Let’s create a list with a another list inside of it.
>>> a = [7, [1, 2], 5, 6, 10, 14, 19, 20]
>>> a
[7, [1, 2], 5, 6, 10, 14, 19, 20]
Let’s take a slice of this list:
>>> a_slice = a[1:4]
>>> a_slice
[[1, 2], 5, 6]
Let’s look at the id of the inner list from both a and a_slice
>>> id(a[1]) == id(a_slice[0])
True
They are the exact same! Python has created a shallow copy here, meaning every mutable object inside of the slice is still the same as it was in the original.
Making an assignment to the inner list
Let’s change the first value in the inner list of a_slice and see if it changes the inner list of a:
>>> inner_list = a_slice[0]
>>> inner_list
[1, 2]>>> inner_list[0] = 99
>>> a_slice
[[99, 2], 5, 6]
>>> a
[7, [99, 2], 5, 6, 10, 14, 19, 20]
The inner list for both variables had its first element changed. That inner list never copied when taking that first slice and therefore it exists in only one unique place in memory.
Chained indexing assignment in one step
We can modify this inner list in a single chain of indexing in one line of code.
>>> # output our current list
>>> a
[7, [99, 2], 5, 6, 10, 14, 19, 20]>>> a[1:5][0][0] = 1000
>>> a
[7, [1000, 2], 5, 6, 10, 14, 19, 20]
Using the copy module to create a deep copy
The standard library comes with the copy module to make a deep copy of your object. A deep copy creates a copy of every single mutable object within your object.
Let’s re-run the code from a couple sections above where we take a slice of a list containing an inner list and this time make a deep copy before checking the id of each inner list.
>>> import copy>>> a = [7, [1, 2], 5, 6, 10, 14, 19, 20]
>>> a_slice = copy.deepcopy(a[1:4])>>> id(a[1]) == id(a_slice[0])
False
Chained Indexing in pandas
Chained indexing happens analogously to pandas DataFrames/Series. Whenever you do two (or more) subset selections one after the other, you are doing chained indexing. Note, that this isn’t 100% indicative that you are doing something wrong but for the vast majority of cases that I have seen, it is.
Let’s walk through several examples of chained indexing on a pandas DataFrame. To simplify matters, we will use some fake data on a small DataFrame.
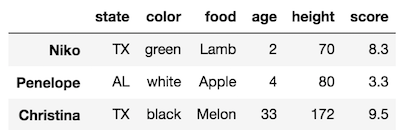
>>> import pandas as pd
>>> df = pd.read_csv('../../data/sample_data.csv', index_col=0)
>>> df

Chained Indexing Example 1
Let’s select the columns food, age, and color and then immediately select just age using chained indexing:
>>> df[['food', 'age', 'color']]['age']
Jane 30
Niko 2
Aaron 12
Penelope 4
Dean 32
Christina 33
Cornelia 69
Name: age, dtype: int64
It might be easier to store each selection to a variable first:
>>> a = ['food', 'age', 'color']
>>> b = 'age'
>>> df[a][b]
Jane 30
Niko 2
Aaron 12
Penelope 4
Dean 32
Christina 33
Cornelia 69
Name: age, dtype: int64
Chained Indexing Example 2
Let’s use .loc to select Niko and Dean along with state, height, and color. Then, let's chain just the indexing operator to select height and color.

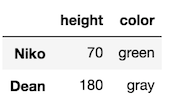
That’s a lot of brackets in the above expression. Let’s separate each selection into their own variables. Below, the variable a is technically a two-item tuple of lists.
>>> a = ['Niko', 'Dean'], ['state', 'height', 'color']
>>> b = ['height', 'color']>>> df.loc[a][b] # outputs same as previous
Chained Indexing Example 3
Let’s use .iloc first to select the rows 2 through 5 and then chain it again to select the last three columns.
>>> df.iloc[2:5].iloc[:, -3:]
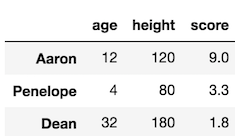
Chained Indexing Example 4
Let’s select the rows Aaron, Dean, and Christina with .loc and then the columns age and food with just the indexing operator.
>>> df.loc[['Aaron', 'Dean', 'Christina']][['age', 'food']]
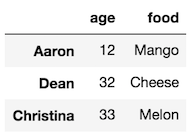
Chained Indexing Example 5
Select all the rows with age greater than 10 with just the indexing operator and then select the score column.
>>> df[df['age'] > 10]['score']
Jane 4.6
Aaron 9.0
Dean 1.8
Christina 9.5
Cornelia 2.2
Name: score, dtype: float64
Identifying Chained Indexing
First, all the examples from above are things you should strive to avoid. All the selections from above could have been reproduced in a much simpler and more direct manner.
As mentioned previously, chained indexing occurs whenever you use the indexers [], .loc, or .iloc twice in a row.
If you are having trouble identifying chained indexing you can look for the following:
- A closed bracket followed by an open bracket — Look for
][as withdf[a][b] .locor.ilocfollowing a closed bracket like in example 3:df.iloc[2:5].iloc[:, -3:]
Another way to determine if you have chained indexing is if you can break the operation up into two lines. For instance, df[a][b] can be broken up into:
>>> df1 = df[a]
>>> df1[b]
Thanks to Tom Augspurger for the first bullet. See his blog post on indexing for more.
Making the examples idiomatic
Let’s re-write all of the above examples idiomatically.
Chained Indexing Example 1 — Idiomatic
>>> # df[['food', 'age', 'color']]['age'] - bad
>>> df['age']
Jane 30
Niko 2
Aaron 12
Penelope 4
Dean 32
Christina 33
Cornelia 69
Name: age, dtype: int64
Chained Indexing Example 2 — Idiomatic
>>> # df.loc[['Niko', 'Dean'], ['state', 'height', 'color']][['height', 'color']] - bad>>> df.loc[['Niko', 'Dean'], ['height', 'color']]
Chained Indexing Example 3 — Idiomatic
>>> # df.iloc[2:5].iloc[:, -3:] - bad
>>> df.iloc[2:5, -3:]
Chained Indexing Example 4 — Idiomatic
>>> # df.loc[['Aaron', 'Dean', 'Christina']][['age', 'food']] - bad
>>> df.loc[['Aaron', 'Dean', 'Christina'], ['age', 'food']]
Chained Indexing Example 5 — Idiomatic
>>> # df[df['age'] > 10]['score'] - bad
>>> df.loc[df['age'] > 10, 'score']
Jane 4.6
Aaron 9.0
Dean 1.8
Christina 9.5
Cornelia 2.2
Name: score, dtype: float64
Why is chained indexing bad?
There are two primary reasons that chained indexing should be avoided if possible.
Two separate operations
The first, and less important reason, is that two separate pandas operations will be called instead of just one.
Let’s take example 4 from above:
>>> df.loc[['Aaron', 'Dean', 'Christina']][['age', 'food']]
When this code is executed, two independent operations are completed. The following is run first:
>>> df.loc[['Aaron', 'Dean', 'Christina']]
The result of this is a DataFrame, and on this temporary and intermediate DataFrame the second and final operation is run to select two columns: [['age', 'food']].
Let’s see this operation written idimoatically:
>>> df.loc[['Aaron', 'Dean', 'Christina'], ['age', 'food']]
There is exactly one operation, a call to the .loc indexer that is passed both the row and column selections simultaneously.
SettingWithCopy warning on assignment
The major problem with chained indexing is when assigning new values to the subset, in which Pandas will usually emit the SettingWithCopy warning.
Let’s use example 5 from above with its chained indexing version to change all the scores of those older than 10 to 99.
>>> df[df['age'] > 10]['score'] = 99/Users/Ted/anaconda3/lib/python3.6/site-packages/ipykernel_launcher.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value insteadSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
"""Entry point for launching an IPython kernel.
The SettingWithCopy warning was triggered. Let's output the DataFrame to see if the assignment happened correctly.
>>> df
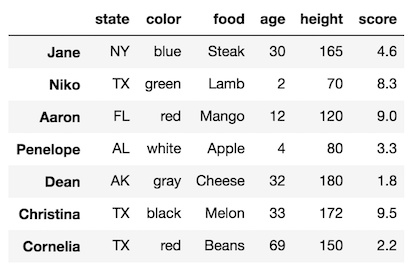
If you are enjoying this article, consider purchasing the All Access Pass! which includes all my current and future material for one low price.
Failed Assignment!
Our DataFrame failed to make the assignment. Let’s break this operation up into two steps to give us more insight into what is happening.
>>> df_temp = df[df['age'] > 10]
>>> df_temp['score'] = 99/Users/Ted/anaconda3/lib/python3.6/site-packages/ipykernel_launcher.py:2: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value insteadSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
The warning is triggered yet again even though there are two lines of code. df_temp is a subset of a DataFrame and any subsets that continue with another subset assignment are liable to trigger the warning. It doesn’t matter if it happens on the same line or not.
Let’s take a look at df_temp:
>>> df_temp
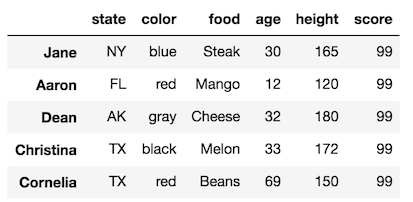
The assignment completed correctly for the intermediate DataFrame but not for our original. The reason for this, is the same reason as to why the chained indexing did not work for the list at the top of this tutorial.
When we run df[df['age'] > 10], pandas creates an entire new copy of the data. So when we try and assign the score column, we are modifying this new copy and not the original. Thus, the name SettingWithCopy make sense: pandas is warning you that you are setting (making an assignment) on a copy of a DataFrame.
How to assign correctly?
You should never use chained indexing to make an assignment. Instead, make exactly a single call to one of the indexers. In this case, we can use .loc to properly make the selection and assignment.
>>> df.loc[df['age'] > 10, 'score'] = 99
>>> df
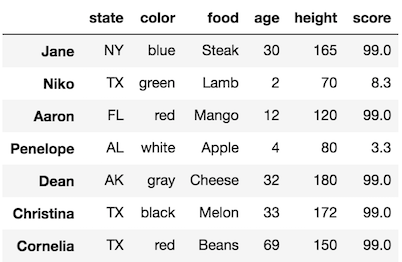
SettingWithCopy example that does assignment
Let’s do another nearly identical chained indexing as the previous example, except we will reverse the order of the chain. We will first select the score column and use boolean indexing to choose the people older than 10 and assign them a score of 0.
First we will, just make the selection (without assignment) so you can see what we are trying to assign.
>>> df['score'][df['age'] > 10]
Jane 99.0
Aaron 99.0
Dean 99.0
Christina 99.0
Cornelia 99.0
Name: score, dtype: float64
Now, let’s make the assignment:
>>> df['score'][df['age'] > 10] = 0/Users/Ted/anaconda3/lib/python3.6/site-packages/ipykernel_launcher.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrameSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
"""Entry point for launching an IPython kernel.
The warning is triggered again. Let’s output the DataFrame:
>>> df
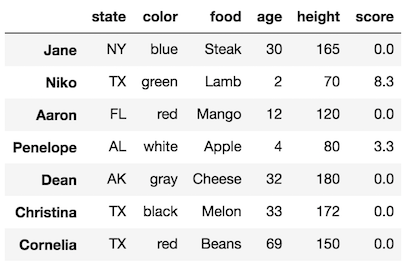
What happened this time?
The first part of the above operation selects the score column. When pandas selects a single column from a DataFrame, pandas creates a view and not a copy. A view just means that no new object has been created. df['score']references the score column in the original DataFrame.
This is analogous to the list example where we assigned an entire list to a new variable. No new object is created, just a new reference to the one already in existence.
Since no new data has been created, the assignment will modify the original DataFrame.
Why is a warning triggered when our operation completed successfully?
Pandas does not know if you want to modify the original DataFrame or just the first subset selection.
For instance, you could have selected the score column as a Series to do further analysis with it without affecting the original DataFrame.
Let’s get a fresh read of our data and see this example:
>>> df = pd.read_csv('../../data/sample_data.csv', index_col=0)>>> s = df['score']
>>> s
Jane 4.6
Niko 8.3
Aaron 9.0
Penelope 3.3
Dean 1.8
Christina 9.5
Cornelia 2.2
Name: score, dtype: float64
Let’s set all the values of scores that are greater than 5 to 0.
>>> s[s > 5] = 0/Users/Ted/anaconda3/lib/python3.6/site-packages/ipykernel_launcher.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrameSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
"""Entry point for launching an IPython kernel.
Why was the warning triggered here?
This last assignment does not use chained indexing. But, the variable s was created from a subset selection of a DataFrame. So it's really not any different than doing the following:
>>> df['score'][df['score'] > 5] = 0
Pandas can’t tell the difference between an assignment like this in a single line versus one on multiple lines. Pandas doesn’t know if you want the original DataFrame modified or not. Let’s take a look at both s and df to see what has happened.
>>> s
Jane 4.6
Niko 0.0
Aaron 0.0
Penelope 3.3
Dean 1.8
Christina 0.0
Cornelia 2.2
Name: score, dtype: float64
s was modified as expected. But, what about our original?
>>> df
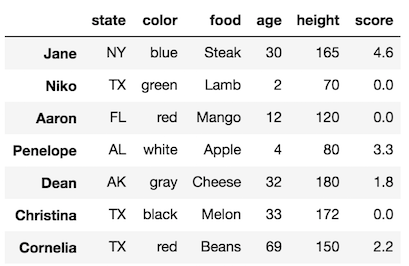
Our original DataFrame has been modified, which means that s is a view and not a copy.
Why is the warning message so useless?
Let’s take a look at what the warning says:
A value is trying to be set on a copy of a slice from a DataFrame
I’m not sure what copy of a slice actually means, but it isn’t what we had in the previous example. s was a view of a column of a DataFrame and not a copy.
What the warning should really say
A better message would look something like this:
You are attempting to make an assignment on an object that is either a view or a copy of a DataFrame. This occurs whenever you make a subset selection from a DataFrame and then try to assign new values to this subset.
Summary of when the SettingWithCopy warning is triggered
In summary, whenever you make a subset selection and then modify the values in that subset selection, you will likely trigger the SettingWithCopy warning.
It might help to see one more example of when the SettingWithCopy is triggered.
Let’s begin by selecting two columns from df into a new variable:
>>> df1 = df[['color', 'age']]
>>> df1

Let’s display the age column from this new DataFrame:
>>> df1['age'] # no warning for output, there is no assignment here
Jane 30
Niko 2
Aaron 12
Penelope 4
Dean 32
Christina 33
Cornelia 69
Name: age, dtype: int64
Let’s add a new column weight:
>>> df1['weight'] = [150, 30, 120, 40, 200, 130, 144]/Users/Ted/anaconda3/lib/python3.6/site-packages/ipykernel_launcher.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value insteadSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
"""Entry point for launching an IPython kernel.
We triggered the warning because df1 is a subset selection from df and we subsequently modified it by adding a new column.
>>> df1
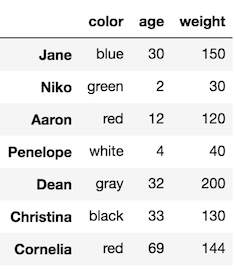
The original is left unchanged.
>>> df
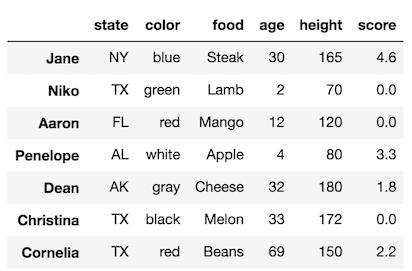
Let’s continue and change all the ages to 99, which will again trigger the warning.
>>> df1['age'] = 99/Users/Ted/anaconda3/lib/python3.6/site-packages/ipykernel_launcher.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value insteadSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
"""Entry point for launching an IPython kernel.>>> df1
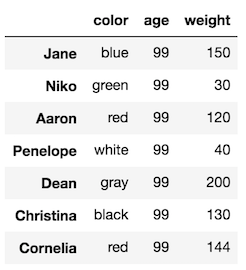
The original was also left unchanged:
>>> df
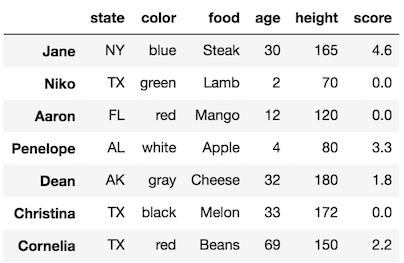
How does pandas know to even to trigger the warning?
In the above example, we created df1, which when modifying the age column, triggered the warning. How did pandas know to do this?
df1 was created by df[['color', 'age']]. During this selection, pandas alters the is_copy or _is_view attributes.
If we call is_copy like a method then we will get the object it was copied from if it is a copy or None will be returned. Let's see its value for df1:
>>> df1.is_copy()

The private attribute _is_view is a boolean:
>>> df1._is_view
False
Let’s check these same attributes for df. Since df was read in directly from a csv it should not be a copy or a view. If it indeed is a copy, then it will return None.
>>> df.is_copy is None
True>>> df._is_view
False
Let’s find out if a single column as a Series is a view or a copy.
>>> food = df['food']
>>> food.is_copy is None # not a copy
True>>> food._is_view
True
Selecting a single column returns a view and not a copy
False Negatives with SettingWithCopy with .loc and .iloc
Unfortunately, when using chained indexing where .loc and .iloc are used as the first indexer, the warning will not get triggered reliably. Let's take a look at an example where no warning is triggered and no change is made to the data.
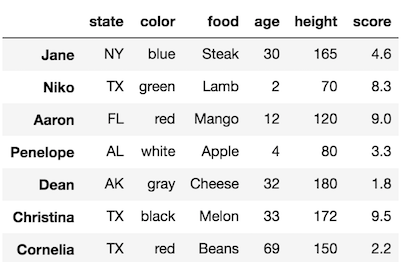
Let’s change the ages of Niko and Dean to 99.
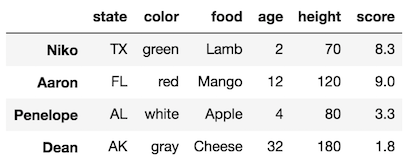
>>> df = pd.read_csv('../../data/sample_data.csv', index_col=0)
>>> df.loc[['Niko','Dean']]['age'] = 99
>>> df
Let’s make a slight change and use slice notation to select all the names from Niko through Dean instead.
>>> df.loc['Niko':'Dean']['age'] = 99
>>> df/Users/Ted/anaconda3/lib/python3.6/site-packages/ipykernel_launcher.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value insteadSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
"""Entry point for launching an IPython kernel.
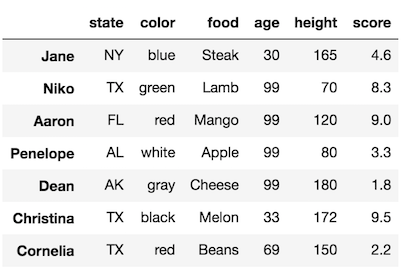
WTF????
By changing from a list to a slice within .loc, the warning is triggered AND the DataFrame is modified. This is craziness.
Some good news
None of the stuff that we have done for SettingWithCopy needs to be memorized. Even I don't know whether a subset selection will return a view or a copy. You don't have to worry about any of that it.
Two common scenarios
You will almost always find yourself in one of two scenarios:
- You want to work with the entire DataFrame and modify a subset of it
- You want to work with a subset of your original DataFrame and modify that subset
Scenario 1 is solved by using exactly one indexer to make the selection and assignment.
Scenario 2 is solved by forcing a copy of your subset selection with the copy method. This will allow you to make changes to this new DataFrame without modifying the original.
Scenario 1 — Working with the entire DataFrame
When you are doing an analysis on a single DataFrame and want to work only on this DataFrame in its entirety then you are in scenario 1.
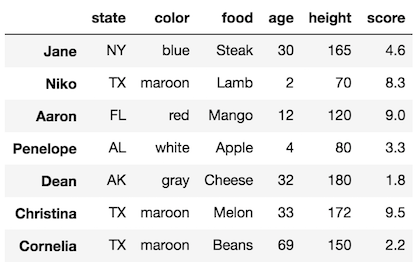
For instance, if we want to change the color of all the people who live in Texas to maroon, we would do this in a single call to the .loc indexer.
>>> df = pd.read_csv('../../data/sample_data.csv', index_col=0)>>> df.loc[df['state'] == 'TX', 'color'] = 'maroon'
>>> df
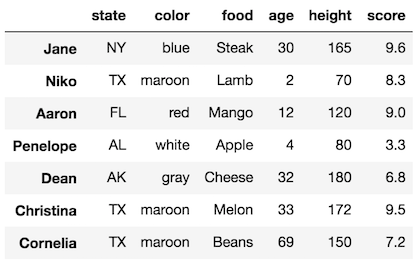
We add 5 to the score of Jane, Dean, and Cornelia like this:

We can change a single cell, such as the age of Aaron to 15:
>>> df.loc['Aaron', 'age'] = 15
>>> df
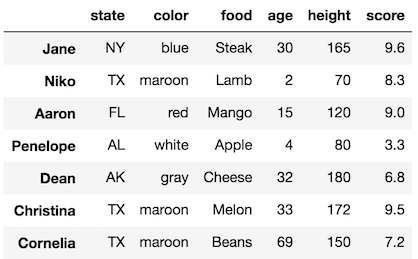
All of these examples involve simultaneous selection of rows and columns, which are the most tempting to do chained indexing on.
Scenario 2
In scenario 2, we would like to select some data from our original DataFrame and do an independent analysis on it separate from the original. For instance, let’s say we wanted to select just the food and height columns into a separate DataFrame.
Let’s go ahead and make this selection:
>>> df1 = df[['food', 'height']]
>>> df1
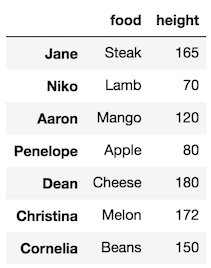
As we saw from above, this DataFrame is still linked to the original DataFrame. We can check the is_copy attribute.
>>> df1.is_copy()
Use the copy method
To get an independent copy, call the copy method like this:
>>> df1 = df[['food', 'height']].copy()
>>> df1.is_copy is None
True
df1 is no longer linked to the original in any way. We can now modify one of its columns without getting the SettingWithCopy warning.
Let’s change the height of every person to 100:
>>> df1['height'] = 100
>>> df1
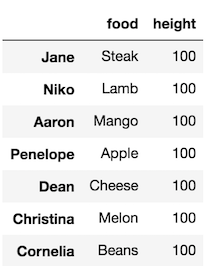
Avoiding ambiguity and complexity
We will now move away from the SettingWithCopy warning and cover some subset selections that I tend to avoid. These subset selections that I personally find either ambiguous or adding complexity to pandas without adding any additional functionality.
However, this does not mean that these subset selections are wrong. They were built into pandas for a purpose and many others make use of them and don’t have a problem using them. So, it will be up to you whether or not you decide to use these upcoming subset selections.
Selecting rows with just the indexing operator
The primary purpose of just the indexing operator is to select column(s) by passing it a string or list of strings. Unexpectedly, this operator completely changes behavior whenever you pass it a slice. For instance, we can select every other row beginning with integer location 1 to the end like this:
>>> df = pd.read_csv('../../data/sample_data.csv', index_col=0)>>> df[1::2]
Even stranger, is that you can make selections by row label as well. For instance, we can select Niko through Dean like this:
>>> df['Niko':'Dean']
Even more bizarre….partial string subset selection
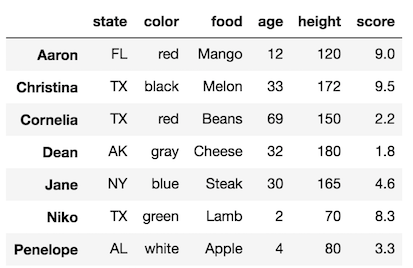
The most bizarre thing is that you can use partial string matches on the index when using a slice with just the indexing operator. For this to work, the index will need to be sorted. Call the sort_index method to do so:
>>> df_sort = df.sort_index()
>>> df_sort
Now, you can do use slice notation with partial strings. For instance, if we wanted to select names that begin with ‘C’ and ‘D’, we would do the following:
>>> df_sort['C':'E']

Technically this slices from the exact label ‘C’ to the exact label ‘E’.
I never do this
I never pass just the indexing operator slices like in these examples for the following reasons:
- It is confusing for there to be multiple modes of operation for an operator — one for selecting columns and the other for selecting rows
- It is not explicit — slicing can happen by both integer location and by label.
If I want to slice rows, I always use .loc/.iloc
The .loc/.iloc indexers are explicit and there will be no ambiguity with them. This follows from the Zen of Python that explicit is better than implicit.
Scalar selection with .at/.iat
Both .at/.iat are indexers that pandas has available to make a selection of one and only one single value. Each of these indexers works analogously to .loc/.iloc.
.at makes its selection only by label and .iat selects only by integer location. They each select a single value. The term scalar is used to refer to a single value.
Let’s take a look at an example of each. First, let’s select Dean’s age.
>>> df.at['Dean', 'age']
32
Notice that a scalar value was returned and not a pandas Series or DataFrame.
We can select the cell at the 5th row and 2nd column like this:
>>> df.iat[5, 2]
'Melon'
What is the purpose of .at/.iat?
These indexers offer no additional functionality. You can select a single value with .loc or .iloc. But, what they do offer, is a performance improvement, albeit a minor one. So, if there is a performance critical part of your code that does lots of scalar selections you could use .at\.iat.
Personally, I never use them as they add needless complexity to the library for a small performance gain.
Summary
- Idiomatic pandas is efficient, easy to read, and common among experts
- It is easy to write non-idiomatic pandas — lots of ways to do the same thing
- Getting the right answer does not guarantee that you are using pandas correctly
- Assignment with chained indexing with a list does not work:
a[2:6][0] = 5- NEVER DO THIS! - Assigning an entire list to a new variable does NOT create a new copy. Both variable names will refer to the same underlying object
- Slicing a list creates a shallow copy
- To make new copies of any mutable objects within a list, you need to do a deep copy
- Chained indexing happens when you make two successive subset selections one directly after the other
- Avoid chained indexing in pandas
- Identify chained indexing — closed then open brackets
][or.loc\.ilocfollowing a bracket like this:df[a].loc[b] - Another way to identify chained indexing is if you can break up the indexing into 2 lines of code.
- Chained indexing is bad because it uses two calls to the indexers instead of one and more importantly triggers the
SettingWithCopywarning when doing an assignment - The
SettingWithCopywarning gets triggered when you make a subset selection and then try to assign new values within this selection. i.e. you have done chained indexing! - Chained indexing is the cause of the
SettingWithCopywarning. Chained indexing can happen in the same line, consecutive lines, or two lines very far apart from each other. - Whenever you make a subset selection, pandas creates either a view or a copy
- A view is a reference to the original DataFrame. No new data has been created.
- A copy means a completely new object with new data that is unlinked from the original DataFrame
- The reason the
SettingWithCopywarning exists, is because you might be trying to make an assignment that actually fails or you might be modifying the original DataFrame without knowing it. - Regardless of why the
SettingWithCopywarning was triggered, you should not ignore it. - You need to go back and understand what happened and probably rewrite your pandas so you don’t trigger the warning
- One of the most common triggers of the
SettingWithCopywarning is when you do boolean selection and then try to set the values of a column like this:df[df['col a'] > 5]['col b'] = 10 - Fix this chained assignment with
.locor.iloclike this:df.loc[df['col a'] > 5, 'col b'] = 10 - You can use
is_copyor the private attribute_is_viewto determine if you have a view or a copy - It is not necessary to know whether you have a view or a copy to write good pandas, because you will likely be in one of two scenarios.
- In Scenario 1, you will be working on one DataFrame and want to change values in it and continue to use it in its entirety
- In Scenario 2, you will make a subset selection, store it to a variable, and want to continue working on it independently from the original data.
- To avoid the
SettingWithCopywarning, use.loc\.ilocfor scenario 1 and thecopymethod with scenario 2. - Personally, I avoid using just the indexing operator to select rows with slices because it is ambiguous.
- I also avoid using
.at\.iatbecause it adds unneeded complexity and adds no increased functionality.
Master Python, Data Science and Machine Learning
Immerse yourself in my comprehensive path for mastering data science and machine learning with Python. Purchase the All Access Pass to get lifetime access to all current and future courses. Some of the courses it contains:
- Master the Fundamentals of Python— A comprehensive introduction to Python (300+ pages, 150+ exercises)
- Master Data Analysis with Python — The most comprehensive course available to learn pandas. (800+ pages and 500+ exercises)
- Master Machine Learning with Python — A deep dive into doing machine learning with scikit-learn constantly updated to showcase the latest and greatest tools. (300+ pages)

Master Data Analysis with Python
Become an expert at using pandas to do data analysis with the comprehensive book Master Data Analysis with Python containing 500+ exercises and projects.
Recent Posts