
Selecting Subsets of Data in Pandas: Part 2
Part 2: Boolean Indexing
This is part 2 of a four-part series on how to select subsets of data from a pandas DataFrame or Series. Pandas offers a wide variety of options for subset selection which necessitates multiple articles. This series is broken down into the following 4 topics.
- Selection with
[],.locand.iloc - Boolean indexing
- Assigning subsets of data
- How NOT to select subsets of data
Become an Expert
If you want to be trusted to make decisions using pandas and scikit-learn, you must become an expert. I have completely mastered both libraries and have developed special techniques that will massively improve your ability and efficiency to do data analysis and machine learning.
- Master Data Analysis with Python — A comprehensive course with 600+ pages, 300+ exercises, multiple projects, and detailed solutions that will help you become a pandas expert.
- Master Machine Learning with Python — My comprehensive guide to become an expert at both the concepts and tools of building a machine learning workflow using Python with scikit-learn.
- Get a sample of the material by enrolling in the FREE Intro to Pandas course.
- Learn directly with me by taking an interactive and fun in-person bootcamp.
Part 1 vs Part 2 subset selection
Part 1 of this series covered subset selection with [], .loc and .iloc. All three of these indexers use either the row/column labels or their integer location to make selections. The actual data of the Series/DataFrame is not used at all during the selection.
In Part 2 of this series, on boolean indexing, we will select subsets of data based on the actual values of the data in the Series/DataFrame and NOT on their row/column labels or integer locations.
Documentation on boolean selection
I always recommend reading the official documentation in addition to this tutorial when learning about boolean selection. The documentation uses more formal examples with dummy data, but is still an excellent resource.
The documentation use the term boolean indexing but you will also see boolean selection.
Boolean Indexing from pandas documentation
Stack Overflow Data
The data that we will use for this tutorial comes from Stack Overflow’s data explorer, which is a fantastic tool to gather an incredible amount of data from the site. You must know SQL in order to use the data explorer. The data explorer allows you to save queries. Take a look at the query I used to collect the data.
The table below contains data on each question asked on stack overflow tagged as pandas.
The first question was asked March 30, 2011. Since then, more than 56,000 questions have been added as of December 2, 2017.
>>> import pandas as pd
>>> import numpy as np>>> so = pd.read_csv('../../data/stackoverflow_qa.csv')
>>> so.head() 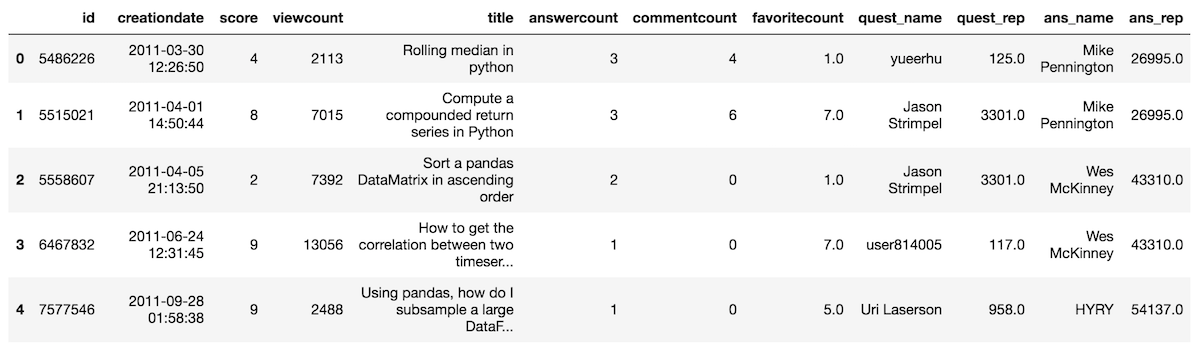
Asking simple questions in plain English
Before we get to the technical definition of boolean indexing, let’s see some examples of the types of questions it can answer.
- Find all questions that were created before 2014
- Find all questions with a score more than 50
- Find all questions with a score between 50 and 100
- Find all questions answered by Scott Boston
- Find all questions answered by the following 5 users
- Find all questions that were created between March, 2014 and October 2014 that were answered by Unutbu and have score less than 5.
- Find all questions that have score between 5 and 10 or have a view count of greater than 10,000
- Find all questions that are not answered by Scott Boston
You will also see examples like this referred to by the term queries.
All queries have criteria
Each of the above queries have a strict logical criteria that must be checked one row at a time.
Keep or Discard entire row of data
If you were to manually answer the above queries, you would need to scan each row and determine whether the row as a whole meets the criterion or not. If the row meets the criteria, then it is kept and if not, then it is discarded.
Each row will have a True or False value associated with it
When you perform boolean indexing, each row of the DataFrame (or value of a Series) will have a True or False value associated with it depending on whether or not it meets the criterion. True/False values are known as boolean. The documentation refers to the entire procedure as boolean indexing.
Since we are using the booleans to select data, it is sometimes referred to as boolean selection. Essentially, we are using booleans to select subsets of data.
Using [ ] and .loc for boolean selection
We will use the same three indexers, [] and .loc from part 1 to complete our boolean selections. We will do so by placing a sequence of booleans inside of these indexer. The sequence will be the same number of rows/values as the DataFrame/Series it is doing the selection on.
The .iloc indexer can be made to work with boolean selection but is almost never used. A small section towards the end will show why it's unnecessary.
Focus on [ ] for now
To simplify things, we will only the brackets, [], which I called just the indexing operator from part 1. We will get to the other indexers a bit later.
Use a small DataFrame to get started
Before we make our first boolean selection, let’s simplify matters and use the first five rows of the stack overflow data as our starting DataFrame.
>>> so_head = so.head()
>>> so_headManually create a list of booleans
For our first boolean selection, we will not answer any interesting ‘English’ queries and instead just select rows with a list of booleans.
For instance, let’s select the first and third rows by creating the following list:
>>> criteria = [True, False, True, False, False]We can pass this list of booleans to just the indexing operator and complete our selection:
>>> so_head[criteria] 
Wait a second… Isn’t [ ] just for column selection?
The primary purpose of just the indexing operator for a DataFrame is to select one or more columns by using either a string or a list of strings. Now, all of a sudden, this example is showing that entire rows are selected with boolean values. This is what makes pandas, unfortunately, one of the most confusing libraries to use.
Operator Overloading
Just the indexing operator is overloaded. This means, that depending on the inputs, pandas will do something completely different. Here are the rules for the different objects you pass to just the indexing operator.
- string — return a column as a Series
- list of strings — return all those columns as a DataFrame
- a slice — select rows (can do both label and integer location — confusing!)
- a sequence of booleans — select all rows where
True
In summary, primarily just the indexing operator selects columns, but if you pass it a sequence of booleans it will select all rows that are True.
Master Data Analysis with Python
Master Data Analysis with Python is an extremely comprehensive course that will help you learn pandas to do data analysis.
I believe that it is the best possible resource available for learning how to data analysis with pandas and provide a 30-day 100% money back guarantee if you are not satisfied.
What do you mean by ‘sequence’?
I keep using the term sequence of booleans to refer to the True/Falsevalues. Technically, the most common built-in Python sequence types are lists and tuples. In addition to a list, you will most often be using a pandas Series as your 'sequence' of booleans.
Let’s manually create a boolean Series to select the last three rows of so_head.
>>> s = pd.Series([False, False, True, True, True])
>>> s
0 False
1 False
2 True
3 True
4 True
dtype: bool>>> so_head[s]
Take care when creating a boolean Series by hand
The above example only worked because the index of both the boolean Series and so_head were the exact same. Let's output them so you can clearly see this.
>>> s.index
RangeIndex(start=0, stop=5, step=1)>>> so_head.index
RangeIndex(start=0, stop=5, step=1)Boolean selection fails when the index doesn’t align
When you are using a boolean Series to do boolean selection, the index of both objects must be the exact same. Let’s create a slightly different Series with a different index than the DataFrame it is indexing on.
>>> s = pd.Series([False, False, True, True, True], index=[2, 3, 4, 5, 6])
>>> s
2 False
3 False
4 True
5 True
6 True
dtype: bool>>> so_head[s]....
IndexingError: Unalignable boolean Series provided as indexer (index of the boolean Series and of the indexed object do not matchIndexingError: Unalignable boolean Series!
If the index of both the boolean Series and the object you are doing boolean selection on don’t match exactly, you will get the above error. This is one reason, as you will below, why you will almost never create boolean Series by hand like this.
Also use NumPy arrays
You can also use NumPy arrays to do boolean selection. NumPy arrays have no index so you won’t get the error above, but your array needs to be the same exact length as the object you are doing boolean selection on.
>>> a = np.array([True, False, False, False, False])
>>> so_head[a]
Never creating boolean Series by hand
You will likely never create a boolean Series by hand as was done above. Instead, you will produce them based on the values of your data.
Use the comparison operators to create boolean Series
The primary method of creating a Series of booleans is to use one of the six comparison operators:
<<=>>===!=
Use comparison operator with a single column of data
You will almost always use the comparison operators on just a single columnor Series of data. For instance, let’s create a boolean Series from the scorecolumn. Let's determine if the score is at least 10.
We select the score column and then test the condition that each value is greater than or equal to 10. Notice that this operations gets applied to each value in the Series. A boolean Series is returned.
>>> criteria = so['score'] >= 10
>>> criteria.head(10)
0 False
1 False
2 False
3 False
4 False
5 False
6 True
7 True
8 True
9 False
Name: score, dtype: boolFinally making a boolean selection
Now that we have our boolean Series stored in the variable criteria, we can pass this to just the indexing operator to select only the rows that have a score of at least 10.
We are going to use the entire so DataFrame for the rest of the tutorial.
>>> so_score_10_or_more = so[criteria]
>>> so_score_10_or_more.head()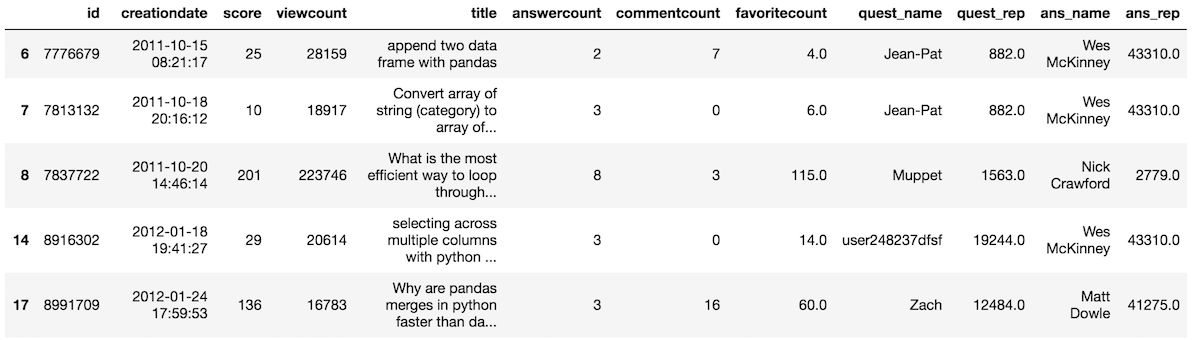
How many rows have a score of at least ten
Just by looking at the head of the resulting DataFrame, we don’t know how many rows passed our criterion. Let’s output the shape of both our original and our resulting DataFrame.
>>> so.shape
(56398, 12)>>> so_score_10_or_more.shape
(1505, 12)Only about 3% of questions get a score of 10 or more.
Boolean selection in one line
Often, you will see boolean selection happen in a single line of code instead of the multiple lines we used above. If the following is confusing for you, then I recommend storing your boolean Series to a variable like I did with criteriaabove.
It is possible to put the creation of the boolean Series inside of just the indexing operator like this.
>>>so[so['score'] >= 10].head()
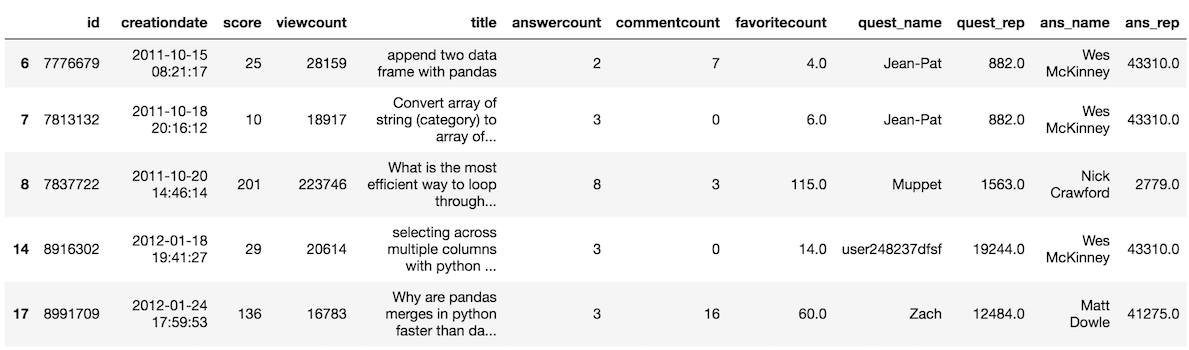
Single condition expression
Our first example tested a single condition (whether the score was 10 or more). Let’s test a different single condition and look for all the questions that are answered by Scott Boston. The ans_name variable holds the display names of the people who posted the accepted answer to the question.
We use the == operator to test for equality and again store this result to the variable criteria. Again, we pass this variable to just the indexing operatorwhich completes our selection.
>>> # step 1 - create boolean Series
>>> criteria = so['ans_name'] == 'Scott Boston'>>> # step 2 - do boolean selection
>>> so[criteria].head()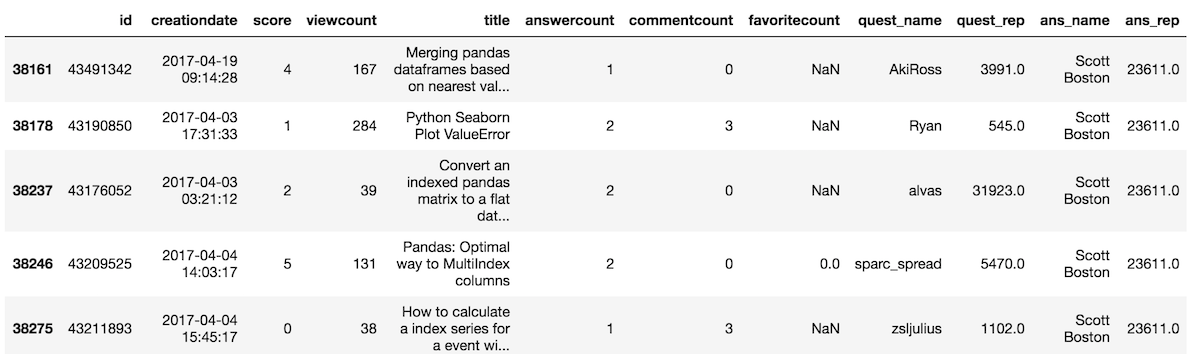
Multiple condition expression
So far, both our boolean selections have involved a single condition. You can, of course, have as many conditions as you would like. To do so, you will need to combine your boolean expressions using the three logical operators and, orand not.
Use &, | , ~
Although Python uses the syntax and, or, and not, these will not work when testing multiple conditions with pandas.
You must use the following operators with pandas:
&for and|for or~for not
Our first multiple condition expression
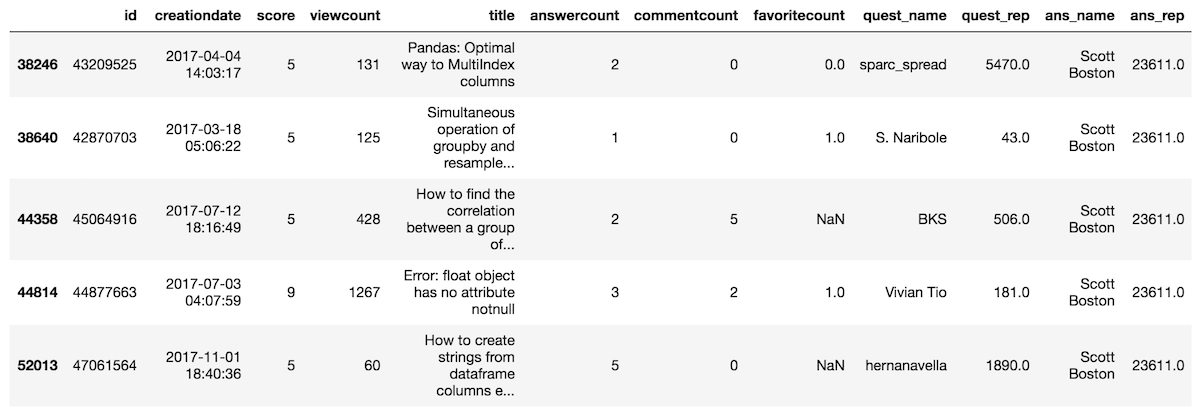
Let’s find all the questions that have a score of at least 5 and are answered by Scott Boston. To begin, we will create two separate variable to hold each criteria.
>>> criteria_1 = so['score'] >= 5
>>> criteria_2 = so['ans_name'] == 'Scott Boston'We will then use the and operator, the ampersand &, to combine them
>>>criteria_all = criteria_1 & criteria_2
We can now pass this final criteria to just the indexing operator
>>>so[criteria_all]
Multiple conditions in one line
It is possible to combine the entire expression into a single line. Many pandas users like doing this, others hate it. Regardless, it is a good idea to know how to do so as you will definitely encounter it.
Use parentheses to separate conditions
You must encapsulate each condition in a set of parentheses in order to make this work.
Each condition will be separated like this:
>>>(so['score'] >= 5) & (so['ans_name'] == 'Scott Boston')
We can then drop this expression inside of just the indexing operator
>>> # same result as previous
>>> so[(so['score'] >= 5) & (so['ans_name'] == 'Scott Boston')]Using an or condition
Let’s find all the questions that have a score of at least 100 or have at least 10 answers.
For the or condition, we use the pipe |
>>> so[(so['score'] >= 100) | (so['answercount'] >= 10)].head() 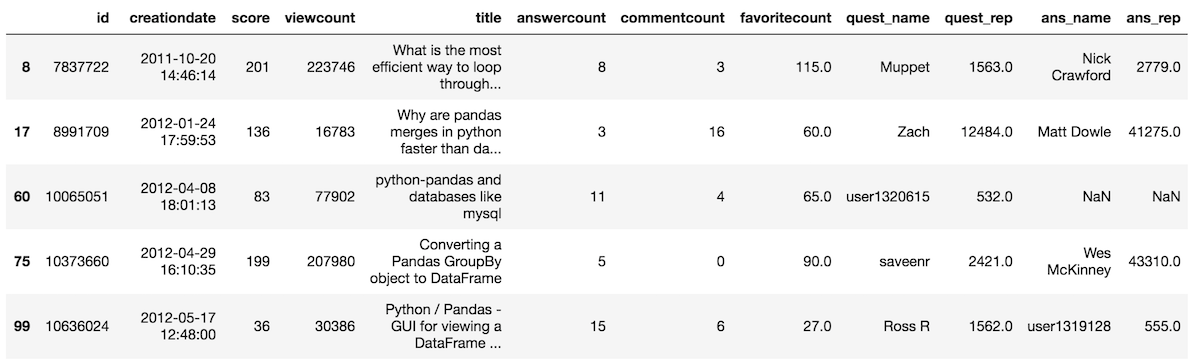
Reversing a condition with the not operator
The tilde character ~ represents the not operator and reverses a condition.For instance, if we wanted all the questions with score greater than 100, we could do it like this:
>>> so[~(so['score'] <= 100)].head()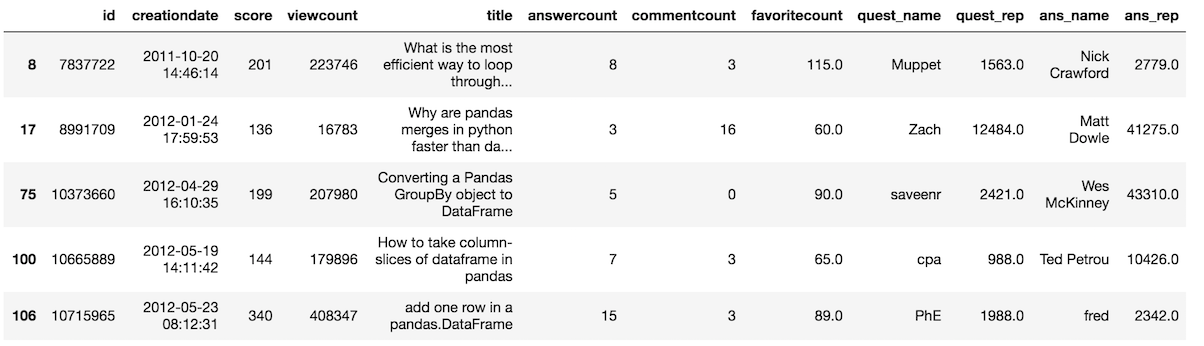
Notice that there were parentheses around the condition ‘score less than equal to 100'. We had to use parentheses here or the operation wouldn't work correctly.
Of course, this trivial example has no need for the not operator and can be replaced with the greater than operator, but it’s easy to verify.
Let’s look back up one example and invert the condition of score at least 100 or number of answers at least 10. To do this, we will have to wrap our entire expression with parentheses like this:
>>> ~((so['score'] >= 100) | (so['answercount'] >= 10))There is a set of parentheses around each inner expression as well.
Complex conditions
It is possible to build extremely complex conditions to select rows of your DataFrame that meet a very specific criteria. For instance, we can select all questions answered by Scott Boston with score 5 or more OR questions answered by Ted Petrou with answer count 5 or more.
With multiple conditions, its probably best to break out the logic into multiple steps:
>>> criteria_1 = (so['score'] >= 5) & (so['ans_name'] == 'Scott Boston')
>>> criteria_2 = (so['answercount'] >= 5) & (so['ans_name'] == 'Ted Petrou')
>>> criteria_all = criteria_1 | criteria_2
>>> so[criteria_all] 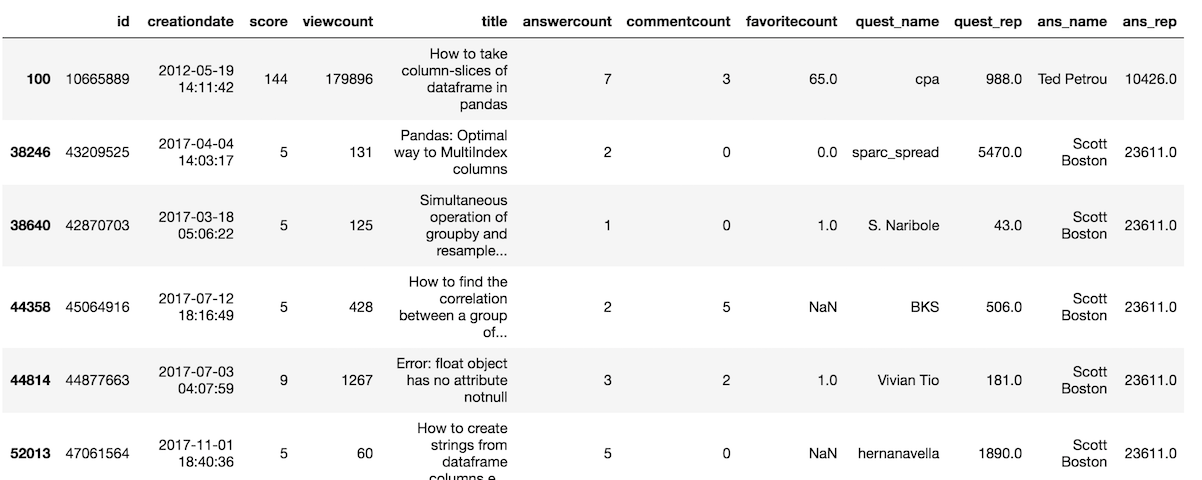
Lots of or conditions in a single column - use isin
Occasionally, we will want to test equality in a single column to multiple values. This is most common in string columns. For instance, let’s say we wanted to find all the questions answered by Scott Boston, Ted Petrou, MaxU, and unutbu.
One way to do this would be with four or conditions.
>>> criteria = ((so['ans_name'] == 'Scott Boston') |
(so['ans_name'] == 'Ted Petrou') |
(so['ans_name'] == 'MaxU') |
(so['ans_name'] == 'unutbu'))An easier way is to use the Series method isin. Pass it a list of all the items you want to check for equality.
>>> criteria = so['ans_name'].isin(['Scott Boston', 'Ted Petrou',
'MaxU', 'unutbu'])
>>> criteria.head()
0 False
1 False
2 False
3 False
4 False
Name: ans_name, dtype: bool>>> so[criteria].head() 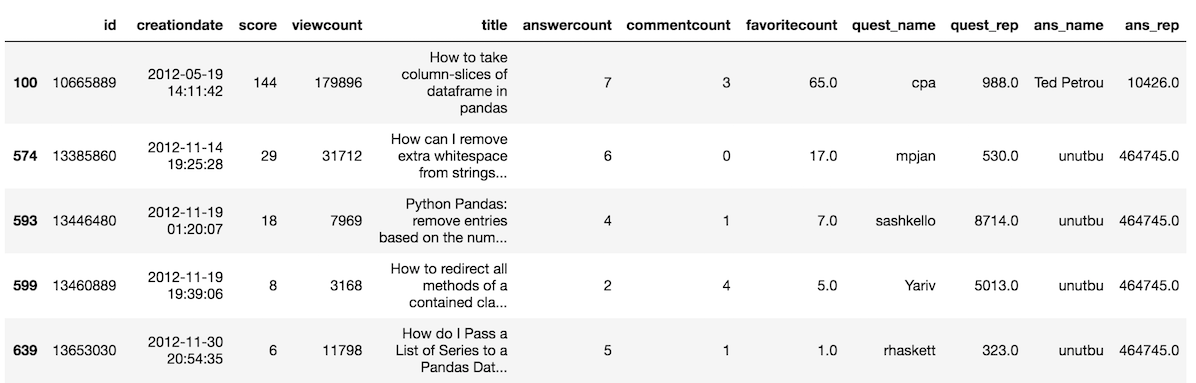
Combining isin with other criteria
You can use the resulting boolean Series from the isin method in the same way you would from the logical operators. For instance, If we wanted to find all the questions answered by the people above and had score greater than 30 we would do the following:
>>> criteria_1 = so['ans_name'].isin(['Scott Boston', 'Ted Petrou',
'MaxU', 'unutbu'])
>>> criteria_2 = so['score'] > 30
>>> criteria_all = criteria_1 & criteria_2
>>> so[criteria_all].tail() 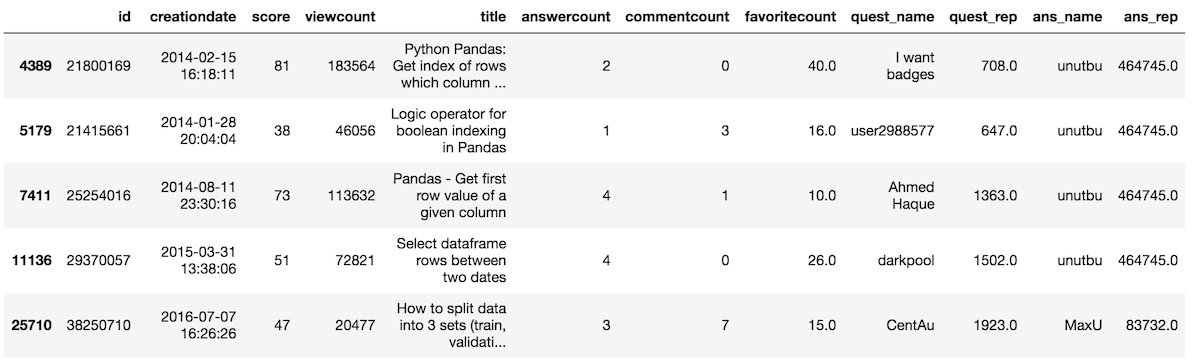
Use isnull to find rows with missing values
The isnull method returns a boolean Series where True indicates a missing value. For instance, questions that do not have an accepted answer have missing values for ans_name. Let's call isnull on this column.
>>> no_answer = so['ans_name'].isnull()
>>> no_answer.head(6)
0 False
1 False
2 False
3 False
4 False
5 True
Name: ans_name, dtype: boolThis is just another boolean Series which we can pass to just the indexing operator.
>>> so[no_answer].head()
An alias of isnull is the isna method. Alias means it is the same exact method with a different name.
Boolean Selection on a Series
All the examples thus far have taken place on the so DataFrame. Boolean selection on a Series happens almost identically. Since there is only one dimension of data, the queries you ask are usually going to be simpler.
First, let’s select a single column of data as a Series such as the commentcount column.
>>> s = so['commentcount']
>>> s.head()
0 4
1 6
2 0
3 0
4 0
Name: commentcount, dtype: int64Let’s test for number of comments greater than 10
>>>criteria = s > 10
>>> criteria.head()
0 False
1 False
2 False
3 False
4 False
Name: commentcount, dtype: bool
Notice that there is no column selection here as we are already down to a single column. Let’s pass this criteria to just the indexing operator to select just the values greater than 10.
>>> s[criteria].head()
17 16
76 14
566 11
763 12
781 19
Name: commentcount, dtype: int64
We could have done this in one step like this
>>>s[s > 10].head()
17 16
76 14
566 11
763 12
781 19
Name: commentcount, dtype: int64
If we wanted to find those comments greater than 10 but less than 15 we could have used an and condition like this:
>>> s[(s > 10) & (s < 15)].head()
76 14
566 11
763 12
787 12
837 13
Name: commentcount, dtype: int64Another possibility is the between method
Pandas has lots of duplicate functionality built in to it. Instead of writing two boolean conditions to select all values inside of a range as was done above,you can use the between method to create a boolean Series. To use, pass it the left and right end points of the range. These endpoints are inclusive.
So, to replicate the previous example, you could have done this:
>>> s[s.between(11, 14)].head()
76 14
566 11
763 12
787 12
837 13
Name: commentcount, dtype: int64Simultaneous boolean selection with rows and column labels with .loc
The .loc indexer was thoroughly covered in part 1 and will now be covered here to simultaneously select rows and columns. In part 1, it was stated that .loc made selections only by label. This wasn't strictly true as it is also able to do boolean selection along with selection by label.
Remember that .loc takes both a row selection and a column selection separated by a comma. Since the row selection comes first, you can pass it the same exact inputs that you do for just the indexing operator and get the same results.
Let’s take a look at a couple examples from above:
>>> # same as above with [ ]
>>> so.loc[(so['score'] >= 5) & (so['ans_name'] == 'Scott Boston')]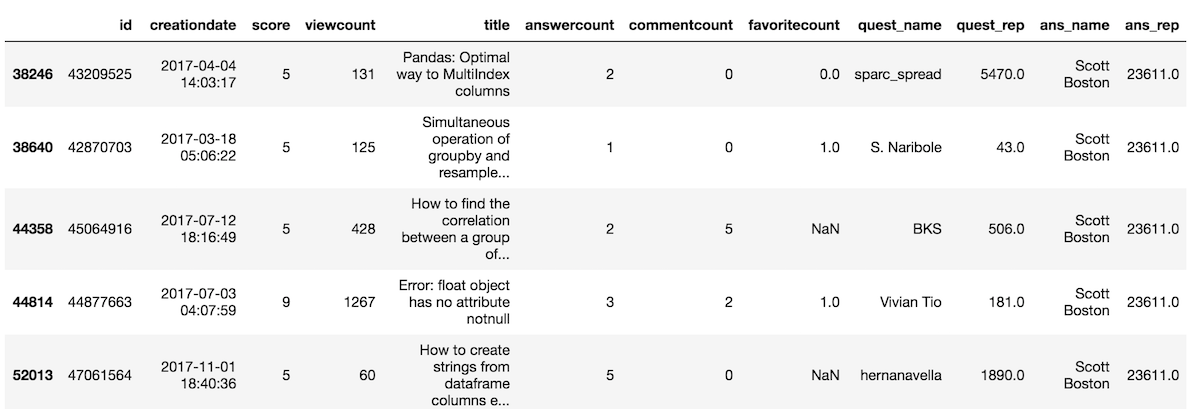
>>> # same as above with [ ]
>>> criteria = so['ans_name'].isin(['Scott Boston', 'Ted Petrou',
'MaxU', 'unutbu'])
>>> so.loc[criteria].head()Separate row and column selection with a comma for .loc
The great benefit of .loc is that it allows you to simultaneously do boolean selection along the rows and make column selections by label.
For instance, let’s say we wanted to find all the questions with more than 20k views but only return the creationdate, viewcount, and ans_name columns. You would do the following.
>>> so.loc[so['viewcount'] > 20000, ['creationdate', 'viewcount',
'ans_name']].head(10)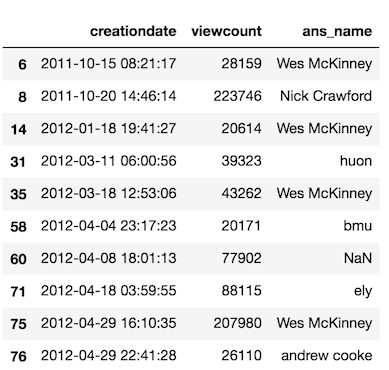
You could have broken each selection into pieces like this:
>>>row_selection = so['viewcount'] > 20000
>>> col_selection = ['creationdate', 'viewcount', 'ans_name']
>>> so.loc[row_selection, col_selection]
Lots of combinations possible with .loc
Remember that .loc can take a string, a list of strings or a slice. You can use all three possible ways to select your data. You can also make very complex boolean selections for your rows.
Let’s select rows with favoritecount between 30 and 40 and every third column beginning from title to the end.
# weird but possible
so.loc[so['favoritecount'].between(30, 40), 'title'::3].head()

Boolean selection for the columns?
It is actually possible to use a sequence of booleans to select columns. You pass a list, Series, or array of booleans the same length as the number of columns to .loc.
Let’s do a simple manual example where we create a list of booleans by hand. First, let’s find out how many columns are in our dataset
>>> so.shape
(56398, 12)Let’s create a list of 12 booleans
>>> col_bools = [True, False, False] * 4
>>> col_bools
[True,
False,
False,
True,
False,
False,
True,
False,
False,
True,
False,
False]Use .loc to select all rows with just the True columns from col_bools.
>>> so.loc[:, col_bools].head() 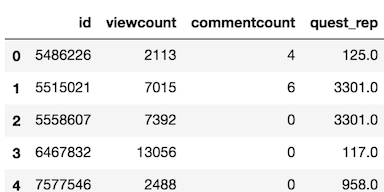
You can simultaneously select rows and columns too. Let’s select the same columns but for rows that have over 500,000 views.
>>> so.loc[so['viewcount'] > 500000, col_bools]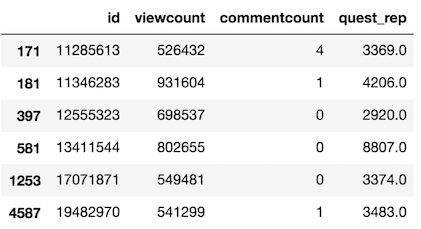
A more practical example
Let’s see a slightly more practical example of doing boolean selection on the columns. Let’s say we flipped 10 coins one-hundred times and store each trial in a column in the DataFrame below
>>> coins = pd.DataFrame(np.random.randint(0, 2, (100, 10)),
columns=list('abcdefghij'))
>>> coins.head()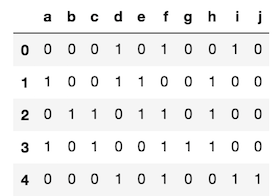
>>> coins.shape
(100, 10)If we are interested in selecting only the columns that have more than 50% heads, we could first take the mean of each column like this.
>>> coin_mean = coins.mean()
>>> coin_meana 0.50
b 0.46
c 0.48
d 0.47
e 0.43
f 0.52
g 0.44
h 0.47
i 0.57
j 0.44
dtype: float64Let’s test the condition that the percentage is greater than .5
>>> coin_mean > .5
a False
b False
c False
d False
e False
f True
g False
h False
i True
j False
dtype: boolFinally, we can use this boolean Series to select only the columns that meet our criteria.
>>>coins.loc[:, coins.mean() > .5].head()

Column to column comparisons
All of the previous Series comparisons happened against a single scalar value. It is possible to create a boolean Series by comparing one column to another. For instance, we can find all the questions where there are more answers than score.
>>> criteria = so['answercount'] > so['score']
>>> so[criteria].head()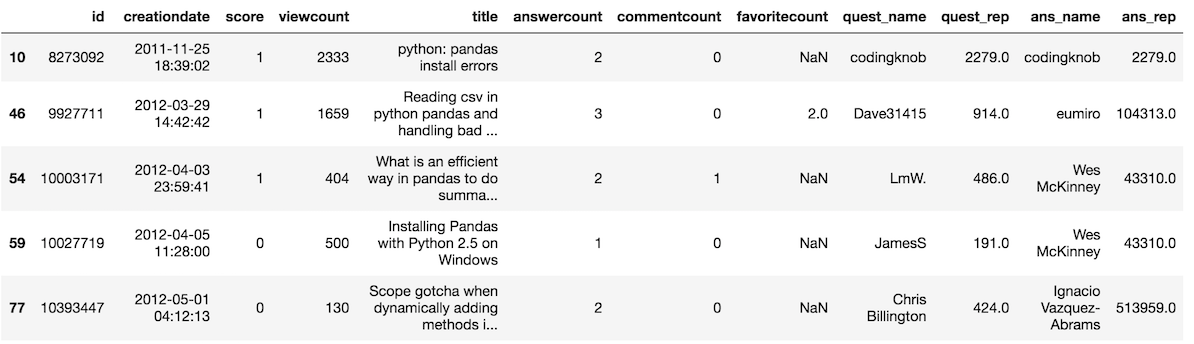
In one line, the above would have looked like this:
>>> so[so['answercount'] > so['score']]Almost never use .iloc with boolean selection
First, remember that .iloc uses INTEGER location to make its selections.
You will rarely use .iloc to do boolean selection and almost always use just the indexing operator or .loc. To see why, let's try and run a simple boolean selection to find all the rows that have more than 100,000 views.
>>> so.iloc[so['viewcount'] > 100000]...NotImplementedError: iLocation based boolean indexing on an integer type is not availableNotImplementedError
The pandas developers have not decided to boolean selection (with a Series) for .iloc so it does not work. You can however convert the Series to a list or a NumPy array as a workaround.
Let’s save our Series to a variable and double-check its type.
>>> criteria = so['viewcount'] > 100000
>>> type(criteria)
pandas.core.series.SeriesLet’s grab the underlying NumPy array with the values attribute and pass it to .iloc
>>> a = criteria.values
>>> so.iloc[a].head()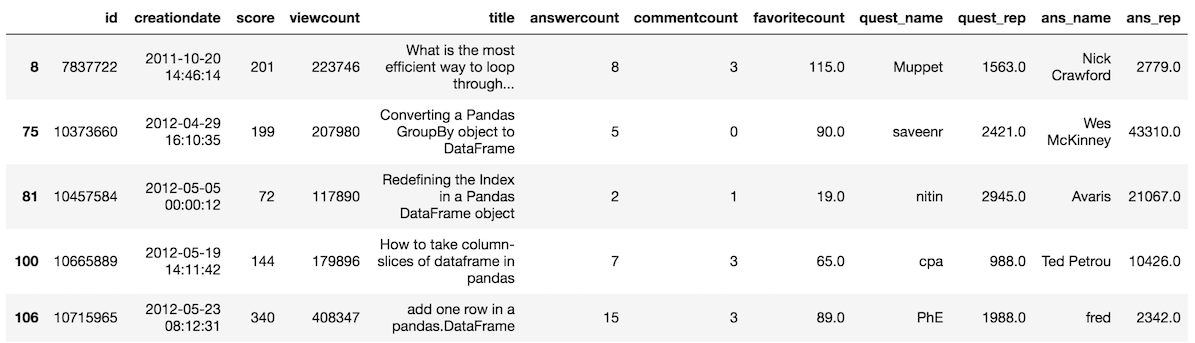
You can make simultaneous column selection as well with integers.
>>> so.iloc[a, [5, 10, 11]].head()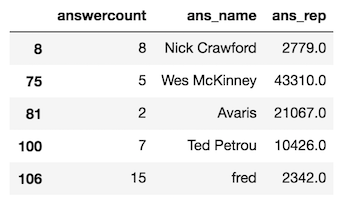
I don’t think I have ever used .iloc for boolean selection as it's not implemented for Series. I added because it's one of the three main indexers in pandas and it's important to know that it's not used much at all for boolean selection.
.loc and [] work the same on a Series for boolean selection
Boolean selection will work identically for .loc as it does with just the indexing operator on a Series. Both the indexers do row selection when passed a boolean Series. Since Series don't have columns, the two indexers are identical in this situation.
>>> s = so['score']
>>> s[s > 100].head()
8 201
17 136
75 199
100 144
106 340
Name: score, dtype: int64>>> s.loc[s > 100].head()
8 201
17 136
75 199
100 144
106 340
Name: score, dtype: int64Summary
- Boolean Indexing or Boolean Selection is the selection of a subset of a Series/DataFrame based on the values themselves and not the row/column labels or integer location
- Boolean selection is used to answer common queries like “find all the female engineers with a salary over 150k/year”
- To do boolean selection, you first create a sequence of True/False values and pass it to a DataFrame/Series indexer
- Each row of data is kept or discarded
- The indexing operators are overloaded — change functionality depending on what is passed to them
- Typically, you will first create a boolean Series with one of the 6 comparison operators
- You will pass this boolean series to one of the indexers to make your selection
- Use the
isinmethod to test for multiple equalities in the same column - Use
isnullto find all rows with missing values in a particular column - Can use the
betweenSeries method to test whether Series values are within a range - You can create complex criteria with the and (
&), or (|), and not (~) logical operators - When you have multiple conditions in a single line, you must wrap each expression with a parentheses
- If you have complex criteria, think about storing each set of criteria into its own variable (i.e. don’t do everything in one line)
- If you are only selecting rows, then you will almost always use just the indexing operator
- If you are simultaneously doing boolean selection on the rows and selecting column labels then you will use
.loc - You will almost never use
.ilocto do boolean selection - Boolean selection works the same for Series as it does for DataFrames
Master Python, Data Science and Machine Learning
Immerse yourself in my comprehensive path for mastering data science and machine learning with Python. Purchase the All Access Pass to get lifetime access to all current and future courses. Some of the courses it contains:
- Master the Fundamentals of Python— A comprehensive introduction to Python (300+ pages, 150+ exercises)
- Master Data Analysis with Python — The most comprehensive course available to learn pandas. (800+ pages and 500+ exercises)
- Master Machine Learning with Python — A deep dive into doing machine learning with scikit-learn constantly updated to showcase the latest and greatest tools. (300+ pages)

Master Data Analysis with Python
Become an expert at using pandas to do data analysis with the comprehensive book Master Data Analysis with Python containing 500+ exercises and projects.
Recent Posts