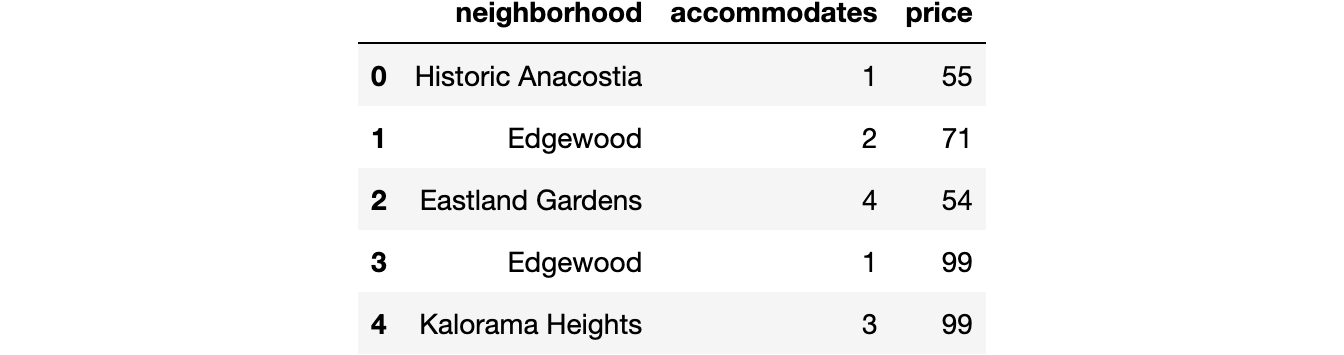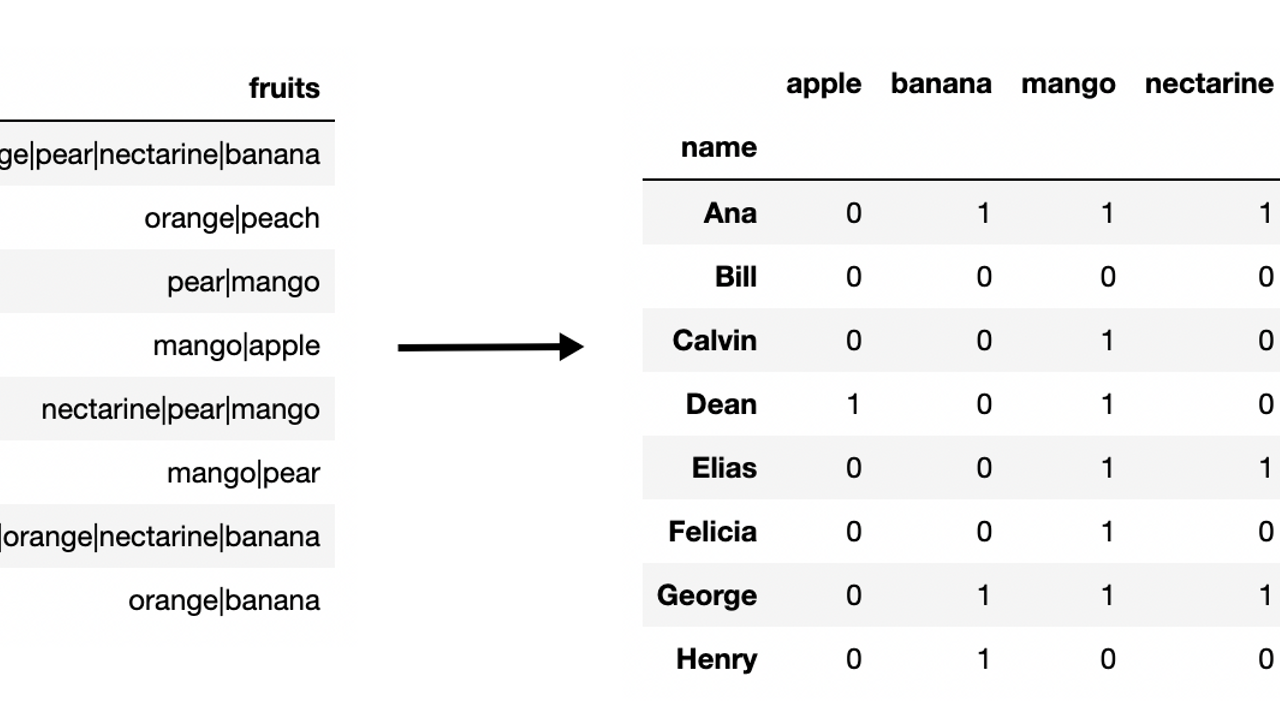


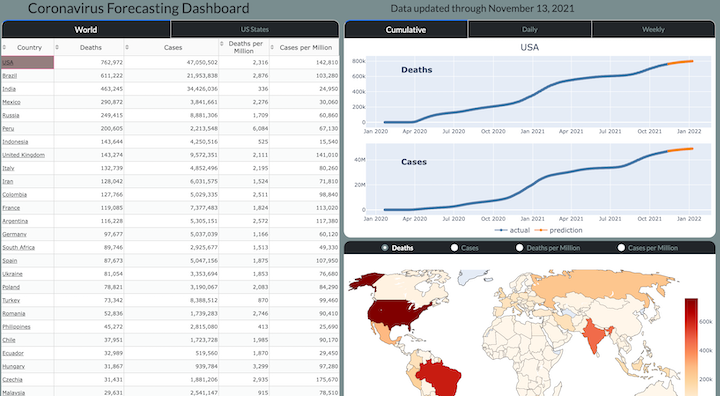


In 2014, I was first introduced to pandas and had no idea how to use it. By 2017, I had written the 500 page book Pandas Cookbook. This is roughly the path I took to mastering pandas for free:
- Read the official documentation
- Practice examples in the documentation
- Flashcards
- Share a full data analysis with others
- Answer old Stack Overflow Questions
- Answer new Stack Overflow Questions
- Teach others in-person or online
- Write pandas blog posts
- Repeat
Read the official documentation
The...